
Where Do You Live in Your Reading?


This post summarizes the key findings from our recent research paper in plain language. For the full paper, see: Selection, Not Salience: The Shape and Limits of Personalization in Social Highlighting
If you want to reread or highlight this newsletter, save it to Glasp.
Here’s a question that sounds philosophical but turns out to be empirically testable:
When you highlight a sentence in an article, how much of that decision is you — and how much is just... what any reader would do?
We’ve been sitting on this question at Glasp for a while. We have millions of highlights from hundreds of thousands of readers. And recently, we decided to stop speculating and start measuring.
The answer surprised us. And it has implications for how we think about personalization, AI, and the future of reading itself.
The Experiment
We designed what researchers call a “co-readership identity control.” The setup is simple:
Take a document that multiple Glasp users have highlighted. Now ask: given a user’s highlighting history, can we predict which highlights in that document are theirs versus someone else’s?
If highlighting is deeply personal — a fingerprint of your mind — then yes, your history should predict your marks. If highlighting is mostly shared (we all find the same things important), then one reader’s history should predict another reader’s highlights just as well.
We ran this experiment at two “altitudes”:
Document selection: Which articles do you choose to read?
Sentence selection: Within an article, which sentences do you highlight?
The results were asymmetric — and fascinating.
Finding #1: Your Individuality Lives in Selection
At the document level, your reading history does predict what you’ll read next. We measured an “identity gap” of +0.12 to +0.17 — meaning your own history is a meaningfully better predictor of your future reads than another reader’s history.
This signal is real. It survived every robustness check we threw at it. And it held up even when we used “hard negatives” — documents on the same topic that you didn’t read, making the test much stricter.
But here’s the nuance: the signal is modest and topic-dominated. Most of what makes your reading history predictive is your interests — the topics you return to. Not some deeper stylistic fingerprint. Not a unique cognitive signature. Just... what you’re curious about.
This aligns with something Austin Kleon writes in Show Your Work!: “You are, in fact, a mashup of what you choose to let into your life.” Your reading selections are a form of self-expression — but it’s expression through curation, not creation.
What Is This “Individuality” Made Of?
We wanted to go deeper. If your reading history predicts your future reads, what exactly is doing the predicting? Is it some deep cognitive style — a preference for conclusions over introductions, for quantitative claims over anecdotes? Or is it simply... your interests?
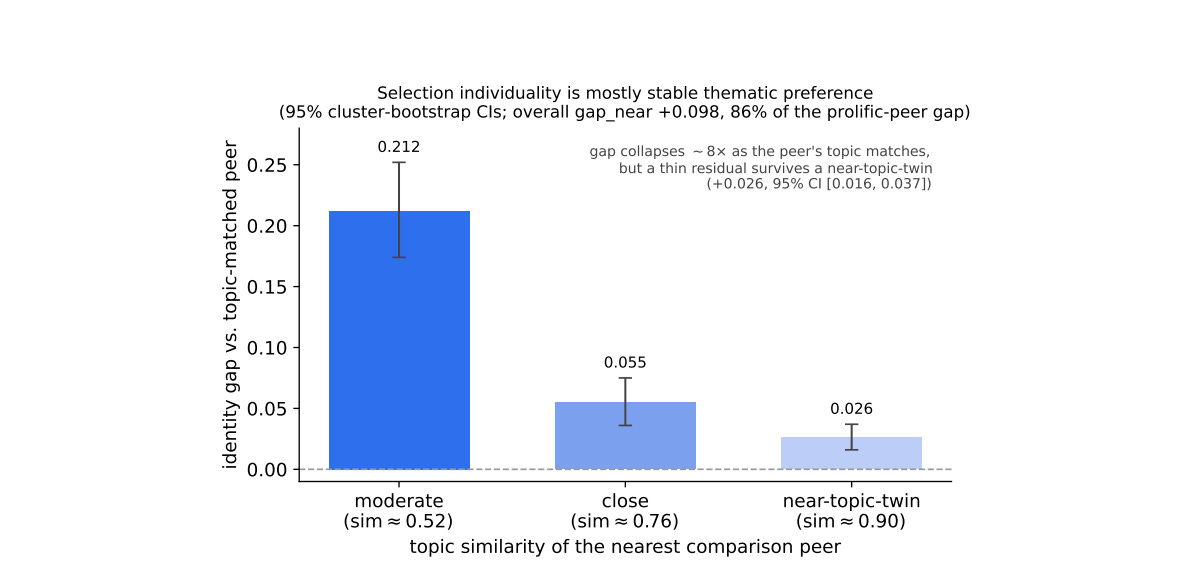
To find out, we ran a “topic decomposition.” Instead of comparing you to a random other reader, we compared you to your topically-nearest peer — someone whose reading history overlaps most with yours in subject matter.
The result was striking: the identity gap shrank by about 8x when the comparison peer was topic-matched.
In other words, most of what makes your reading history “yours” is the topics you return to. Not a unique highlighting style. Not a cognitive fingerprint. Just... what you’re curious about.
This might sound deflating — “I’m just my interests?” — but we think it’s actually liberating. Your curiosity is your signature. The rabbit holes you go down, the questions you keep asking, the threads you keep pulling — that’s the individuality that shows up in your data.
A thin residual does survive even against a near-topic-twin (about +0.026 in our measurement). We can’t tell if this is a genuine “style” signal or just finer-grained topic we couldn’t capture. But either way, it’s small. The main story is clear: your individuality in selection is mostly stable thematic preference.
Finding #2: Within a Document, We’re All the Same
Here’s where it gets humbling.
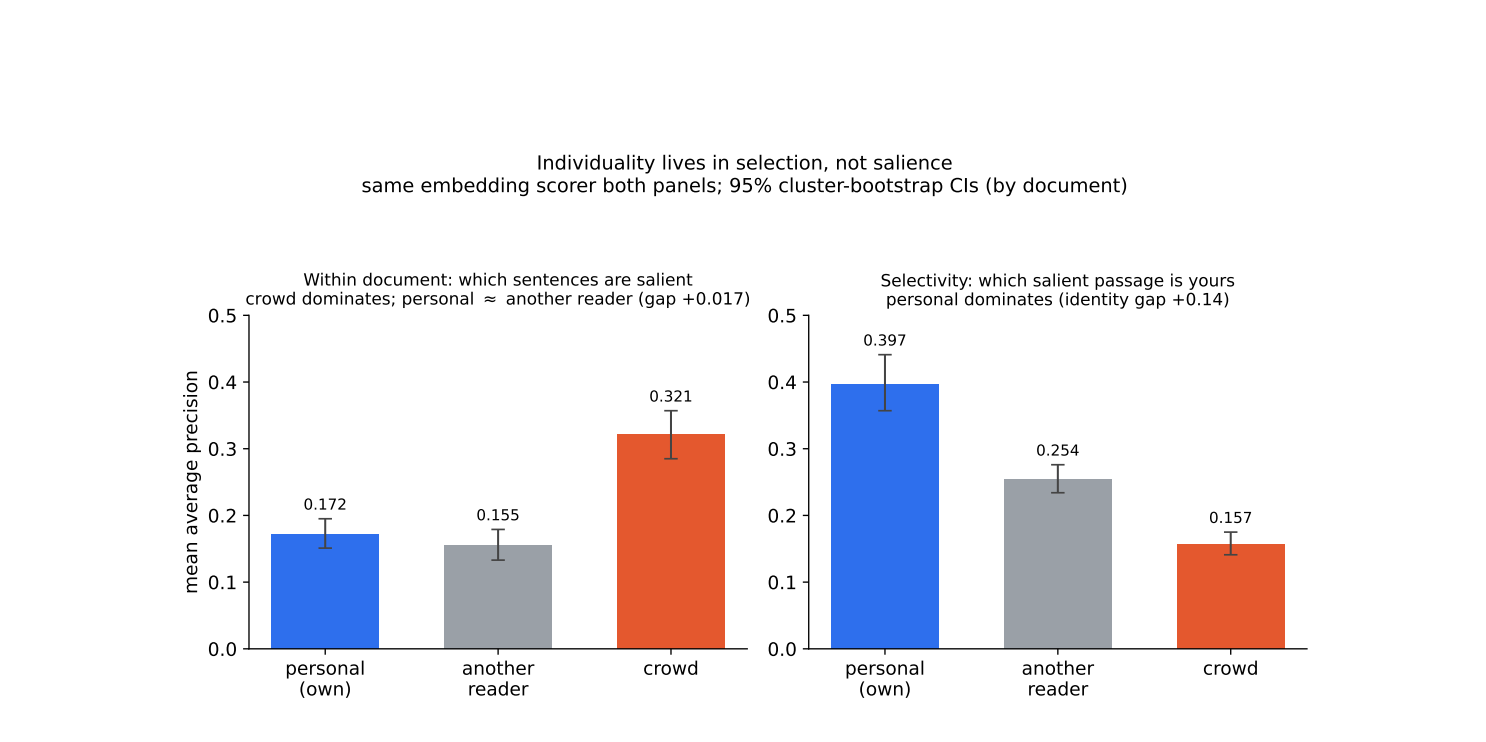
At the sentence level — which sentences you highlight within an article — the personal signal nearly vanishes. The identity gap drops to +0.017. That’s almost nothing.
What does this mean? It means that when two people read the same article, they highlight remarkably similar sentences. The “salience” — what feels important, what deserves a yellow mark — is shared.
This isn’t a flaw in the data. It’s a feature of human cognition. We are social animals. We evolved to attend to similar things. When a sentence contains a key insight, a surprising claim, or a memorable turn of phrase, most readers notice it.
David Perell calls writing a “Serendipity Vehicle” — a way to send ideas into the world and see who resonates. Our data suggests the reverse is also true: reading is a convergence vehicle. We converge on what matters.
Finding #3: Personalized AI Doesn’t Beat the Basics
We didn’t stop at measurement. We also tested whether personalization could be useful.
Imagine a feature: you open a new article, and an AI pre-highlights the sentences you would probably mark, based on your history. A personalized auto-highlight. Sounds useful, right?
We built a two-stage system to test this:
Stage 1: An impersonal model proposes candidate sentences (the ones “a typical reader” would highlight).
Stage 2: A personal model re-ranks those candidates based on your highlighting history.
The result? Personal re-ranking didn’t help. In fact, it performed worse than just trusting the impersonal Stage 1 order.
And here’s the kicker: the Stage 1 model — a state-of-the-art LLM, including frontier models like GPT-5.5 — couldn’t even beat a trivial “lead baseline.” That’s just ranking sentences by their position in the document: first sentences first.
Let that sink in. A frontier AI model, asked to predict what humans would highlight, performed worse than “just read the beginning of each paragraph.”
We tested this carefully. The lead baseline — simply ranking earlier sentences higher — achieved an average precision of 0.237. The LLM? Around 0.22–0.25, depending on the model. The lead baseline also beat the user’s own highlighting history as a predictor (0.185). Knowing which sentences come first in each paragraph predicts what you’ll highlight better than knowing your entire reading history.
But here’s what’s interesting: the crowd still beats the lead baseline decisively (+0.103 in average precision). So the crowd isn’t just picking up on document structure — it’s capturing something more. Real human attention, aggregated.
This isn’t a failure of AI. It’s a revelation about salience. Human attention is governed by structural cues — position, paragraph breaks, topic sentences — that are so fundamental they’re hard to beat. LLMs can summarize, but they don’t see documents the way readers do. They don’t have the embodied experience of scanning a page, of eyes drawn to the opening line of a section, of attention flagging in the middle and reviving at the end.
Finding #4: A Few Dozen Highlights Is Enough
One practical question: how much history do you need before your “individuality” becomes visible?
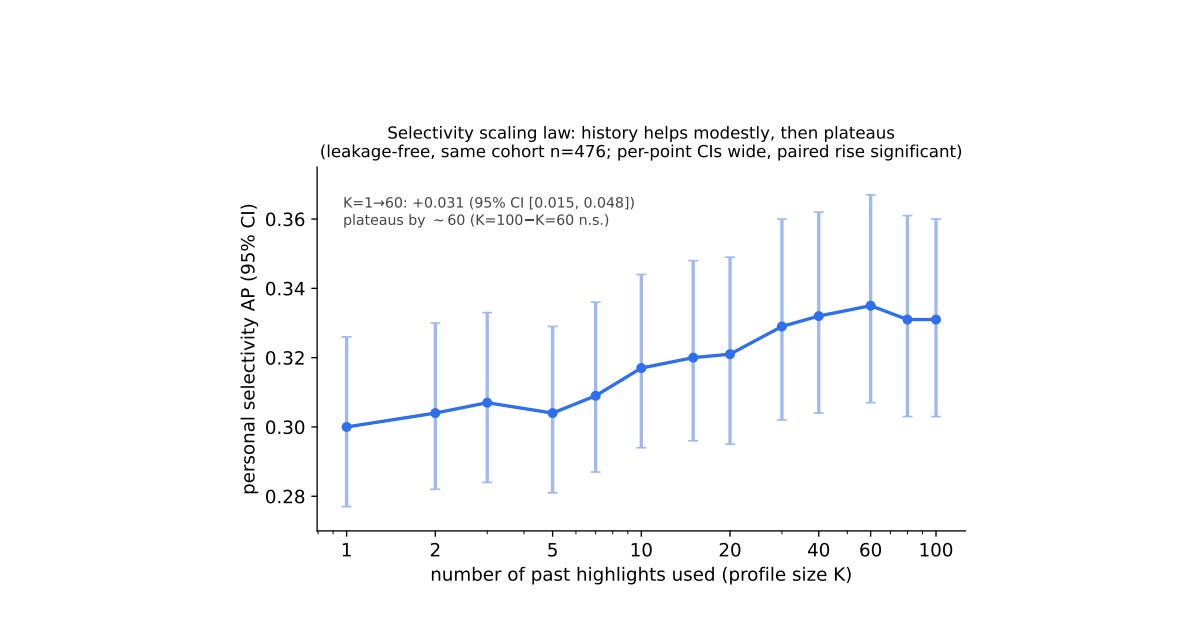
We ran a scaling analysis, varying the number of past highlights used to build a user’s profile from 1 to 100. The answer: a few dozen highlights is enough. After that, more history doesn’t help.
At K=1 (just one past highlight), the model’s predictive power is already above chance. By K=20, you’ve captured about two-thirds of the maximum signal. By K=60, the curve plateaus — adding more highlights from 60 to 100 makes no measurable difference.
This is good news for new users: you don’t need years of history to have a meaningful profile. A month of active highlighting is probably enough.
But it’s also a ceiling. Unlike the crowd — whose predictive accuracy keeps rising as more readers contribute — your individual signal maxes out quickly. The crowd is data-hungry; your individuality is data-cheap.
This asymmetry reinforces our main finding: the path to better predictions isn’t deeper individual modeling. It’s broader aggregation.
Why This Matters for Glasp
At Glasp, we’ve always believed in the power of social highlighting. This research gives us the science behind the intuition.
1. Popular Highlights aren’t noise. They’re signal.
When you see “87 people highlighted this sentence,” you’re not seeing groupthink. You’re seeing collective salience — the distilled attention of many minds. Our data shows that this shared layer is the layer. It’s where the information lives.
This is why we invested in Popular Highlights as a core feature. It’s not a popularity contest. It’s a knowledge primitive.
2. Personalization has a ceiling.
The tech industry has spent a decade promising hyper-personalization: feeds tailored to you, recommendations that know you better than you know yourself. Our research suggests this promise has limits — at least in reading.
Your “you-ness” shows up in what you choose to read. But once you’re inside a document, you’re not that different from other readers. The personal residual is a whisper.
This doesn’t mean personalization is useless. It means it belongs at the selection layer — helping you discover what to read next — not at the salience layer, trying to guess which sentences you’d mark.
3. Aggregation beats personalization.
If individual signals are modest and salience is shared, then the path to better reading tools isn’t deeper models of you. It’s better aggregation of everyone.
This is the Glasp thesis in a nutshell: your highlights, combined with millions of others, create something no individual can produce alone. A collectively annotated web. A living marginalia. What we call the “Chain of Readers.”
swyx talks about “learning exhaust” — the byproduct of learning in public. Highlights are reading exhaust. And when you aggregate reading exhaust at scale, you get a map of human attention.
The Limits of What We Found
A few caveats, because intellectual honesty matters:
Our population is self-selected. Glasp users are not “readers in general.” They’re people who install a highlighting tool. The results describe social highlighting on a co-readership platform.
Topic dominates the signal. Most of the predictive power in your reading history is your interests, not some deeper cognitive style. We couldn’t cleanly separate “topic” from “non-thematic style.”
The LLM result is zero-shot. We didn’t fine-tune or prompt-engineer. A heavily optimized model might do better. But the point stands: off-the-shelf AI isn’t a shortcut to human salience.
What This Means for You
If you’re a Glasp user, here’s the practical takeaway:
Trust the crowd. When you see a sentence that dozens of people highlighted, it’s probably worth your attention. That’s not conformity — it’s signal.
Your selections matter. The articles you choose, the topics you return to, the rabbit holes you go down — that’s where your individuality expresses itself. Your Glasp profile isn’t just a log. It’s a portrait.
Highlight freely. Don’t worry about whether your highlights are “unique.” They don’t need to be. They’re your contribution to a collective layer that benefits everyone.
And if you’re building AI tools for reading? Our research suggests a counterintuitive direction: don’t personalize harder. Aggregate better.
Conclusion
We set out to measure where individuality lives in reading. The answer: it lives in selection, not salience.
What you read is personal. Which sentences you highlight is shared. And the path to smarter reading isn’t deeper personalization — it’s better aggregation of the collective.
This is what Glasp is for. Not to build a mirror of you, but to weave your highlights into a tapestry of us.
📄 Read the full paper: Selection, Not Salience: The Shape and Limits of Personalization in Social Highlighting
📄 Background reading: This paper builds on our earlier work, Personal Salience: Highlighting Is Social, but Individuality Lives in Selection, which first identified where individuality surfaces in highlighting behavior.
Partner With Glasp
We currently offer newsletter sponsorships. If you have a product, event, or service you’d like to share with our community of learning enthusiasts, sponsor an edition of our newsletter to reach engaged readers.
This is amazing! Does anyone at Glasp have a data science background to have done this study, did you outsource, or did you conduct it with the help of AI? I hope to read the paper when I have more time 🙏🏼
Kei, my sincerest apologies are in order. I offer them to you. I didn't realize that the error was inadvertent. I'm seeing so much garbling of the English language on the Internet these days, I just lost my head. It's good to hear from you and know that you are quite literate. Thank you for replying. 🙏